Học tập thuật toán là một trong những yêu cầu cơ bản để trở thành các lập trình viên. Đối với các sinh viên ngành tin học và những ai yêu thích lập trình, việc học thuật toán còn là một thú vui, giúp nâng cao tư duy logic và làm phong phú thêm kiến thức về việc xây dựng các giải thuật cho các bài toán mới. Trong bài báo nhỏ này tôi xin đưa ra một số bài toán nhỏ, để qua đó trình bày một số thuật toán khá tinh tế để giải quyết chúng, mong rằng bài báo sẽ mang lại cho các bạn độc giả những điều thú vị. Bài toán 1: Cho một dãy số nguyên a có N phần tử và một số nguyên k. Hãy xác định xem trong dãy a có tồn tại hai số nguyên a[i] và a[j] sao cho k là trung bình cộng của a[i] và a[j] (i≠j). Bài toán này còn có thể chuyển thành bài toán tìm xem có tồn tại hai phần tử a[i], a[j] mà k là hiệu của chúng không. Thuật toán dành cho bài toán 1 cũng không có gì quá phức tạp, chỉ cần hai vòng lặp lồng nhau, một dành cho chỉ số i và một dành cho chỉ số j (chạy từ 0 tới N-1) sau đó trong thân của hai vòng lặp này ta kiểm tra điều kiện a[i] + a[j] = 2*k hay không. Đoạn chương trình cài đặt cụ thể như sau:  Các bạn có thể dễ dàng nhận thấy thuật toán trên có độ phức tạp 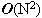 . Tuy nhiên xem xét kỹ hơn một chút chúng ta thấy rằng có thể cải tiến để nhận được thuật toán tốt hơn cho bài toán 1. Để ý vòng lặp thứ 2 với chỉ số j chính là áp dụng của thuật toán tìm kiếm tuyến tính đối với dãy a (điều kiện tìm kiếm là tìm xem có tồn tại a[i], a[j] thỏa mãn điều kiện của bài toán 1 hay không), nên chúng ta có thể thay bằng thuật toán tìm kiếm nhị phân với độ phức tạp . Tuy nhiên xem xét kỹ hơn một chút chúng ta thấy rằng có thể cải tiến để nhận được thuật toán tốt hơn cho bài toán 1. Để ý vòng lặp thứ 2 với chỉ số j chính là áp dụng của thuật toán tìm kiếm tuyến tính đối với dãy a (điều kiện tìm kiếm là tìm xem có tồn tại a[i], a[j] thỏa mãn điều kiện của bài toán 1 hay không), nên chúng ta có thể thay bằng thuật toán tìm kiếm nhị phân với độ phức tạp 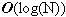 . Thay vì tìm điều kiện tồn tại a[i]+a[j] == 2*k, chúng ta sẽ tìm xem có tồn tại chỉ số j mà a[j] = 2*k – a[i] hay không, cụ thể nếu 2*k – a[i] > a[i] thì chúng ta sẽ tìm trên mảng a[i+1..N-1] còn nếu 2*k – a[i] < a[i] thì ta sẽ tìm trên mảng a[0..i-1]. Để có thể thực hiện thuật toán tìm kiếm nhị phân chúng ta sẽ sắp xếp dãy a trước khi tiến hành tìm kiếm, thuật toán sắp xếp được chọn ở đây sẽ là thuật toán quick sort, có độ phức tạp là . Thay vì tìm điều kiện tồn tại a[i]+a[j] == 2*k, chúng ta sẽ tìm xem có tồn tại chỉ số j mà a[j] = 2*k – a[i] hay không, cụ thể nếu 2*k – a[i] > a[i] thì chúng ta sẽ tìm trên mảng a[i+1..N-1] còn nếu 2*k – a[i] < a[i] thì ta sẽ tìm trên mảng a[0..i-1]. Để có thể thực hiện thuật toán tìm kiếm nhị phân chúng ta sẽ sắp xếp dãy a trước khi tiến hành tìm kiếm, thuật toán sắp xếp được chọn ở đây sẽ là thuật toán quick sort, có độ phức tạp là 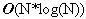 . Vòng lặp đối với chỉ số i có độ phức tạp là . Vòng lặp đối với chỉ số i có độ phức tạp là 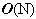 nên đoạn thuật toán tìm kiếm sẽ có độ phức tạp là và do đó thuật toán cuối cùng sẽ có độ phức tạp là . Cài đặt cụ thể của thuật toán như sau: nên đoạn thuật toán tìm kiếm sẽ có độ phức tạp là và do đó thuật toán cuối cùng sẽ có độ phức tạp là . Cài đặt cụ thể của thuật toán như sau:  Về hàm qsort() của C/C++ các bạn có thể tra thêm với Turbo C 3.0 để biết thêm chi tiết, ở đây chúng ta chỉ cần chú ý là khi gọi tới hàm này cần có một hàm trợ giúp làm nhiệm vụ so sánh các phần tử trong dãy cần sắp, và khi gọi hàm cần chỉ rõ kích thước của một phần tử quan toán tử sizeof của C/C++. Bài toán 2: Hãy viết chương trình in ra tất cả các số nguyên tố có hai chữ số. Có thể nói đây là một bài toán khá đơn giản, chỉ cần có một hàm kiểm tra tính nguyên tố (các bạn có thể tham khảo bài viết Số nguyên tố của tôi để biết thêm về thuật toán kiểu này), sau đó chạy một vòng lặp với các số có hai chữ số là xong.Tuy nhiên sẽ là thế nào nếu như đề bài có thêm yêu cầu xây dựng thuật toán tốt nhất cho bài toán trên. Chúng ta sẽ đi tìm một thuật toán tốt hơn ý tưởng sử dụng hàm kiểm tra tính nguyên tố của mỗi số nguyên. Có thể nhận thấy rằng các số nguyên tố có hai chữ số (hay bất cứ số nguyên tố nào lớn hơn 10) đều chữ số cuối thuộc tập {1, 3, 7, 9}. Lại do các số nguyên tố cần tìm đều là các số nhỏ hơn 100 (có hai chữ số) nên chúng chỉ có thể có các ước số nguyên tố nhỏ hơn 10, hay chính xác là chỉ có thể là 3 hoặc 7 (không có 2, 5). Vậy ta chỉ cần tạo ra các số có hai chữ số mà đảm bảo chúng có chữ số kết thúc thuộc tập {1, 3, 7, 9} và kiểm tra xem chúng có chia hết cho 3 và 7 không là đủ. Đoạn chương trình cài đặt cụ thể của thuật toán là:  Bài toán 3 (bài toán tìm điểm yên ngựa của ma trận): Cho một ma trận kích thước NxM (N hàng, M cột). Hãy tìm xem trên ma trận có tồn tại phần tử a[i][j] nào vừa là phần tử nhỏ nhất của hàng i, lại vừa là phần tử lớn nhất của cột j hay không. Đây có lẽ là một bài toán khá quen thuộc với đa số các bạn độc giả đã học về cấu trúc dữ liệu và giải thuật. Thuật toán để giải quyết bài toán cũng khá đơn giản: ta sử dụng hai vòng lặp cho các chỉ số hàng (i) và cột (j), với mỗi phần tử a[i][j] đó ta sẽ tìm phần tử nhỏ nhất của hàng i, gọi là x, tìm phần tử lớn nhất của cột j, gọi là y, cuối cùng so sánh xem x, y và a[i][j] có bằng nhau hay không để đi đến kết luận a[i][j] có là phần tử yên ngựa hay không (kết quả là có nếu a[i][j] bằng x, và bằng y). Việc tìm x sẽ tiến hành với M phần tử của hàng i, việc tìm y sẽ tiến hành với N phần tử của cột j nên thuật toán sẽ có độ phức tạp là 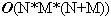 . N*M tương ứng với hai vòng lặp của biến i và biến j. Thuật toán này có thể cải tiến nếu chúng ta nhận thấy rằng: việc tìm các giá trị x (có N giá trị x như vậy, do có N hàng), giá trị y (có M giá trị y như vậy) trong thân vòng lặp tương ứng của các biến i, j là chưa tối ưu. Chúng ta có thể tìm N giá trị nhỏ nhất của các hàng và lưu vào mảng minh[0..N-1], thuật toán tương ứng sẽ có độ phức tạp là . N*M tương ứng với hai vòng lặp của biến i và biến j. Thuật toán này có thể cải tiến nếu chúng ta nhận thấy rằng: việc tìm các giá trị x (có N giá trị x như vậy, do có N hàng), giá trị y (có M giá trị y như vậy) trong thân vòng lặp tương ứng của các biến i, j là chưa tối ưu. Chúng ta có thể tìm N giá trị nhỏ nhất của các hàng và lưu vào mảng minh[0..N-1], thuật toán tương ứng sẽ có độ phức tạp là 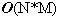 , do ta tìm N lần, mỗi lần tìm trong một hàng có M phần tử. Tương tự chúng ta sẽ tìm các phần tử lớn nhất của các cột và lưu vào mảng maxc[0..M-1], thuật toán này cũng có độ phức tạp là . Cuối cùng trong vòng lặp với các biến i, j chúng ta chỉ cần so sánh a[i][j] với minh[i] và maxc[j], nếu ba số này bằng nhau thì a[i][j] chính là một phần tử yên ngựa. Thuật toán cải tiến cho bài toán 3 này có độ phức tạp , tất nhiên là tốt hơn so với thuật toán ban đầu có độ phức tạp . , do ta tìm N lần, mỗi lần tìm trong một hàng có M phần tử. Tương tự chúng ta sẽ tìm các phần tử lớn nhất của các cột và lưu vào mảng maxc[0..M-1], thuật toán này cũng có độ phức tạp là . Cuối cùng trong vòng lặp với các biến i, j chúng ta chỉ cần so sánh a[i][j] với minh[i] và maxc[j], nếu ba số này bằng nhau thì a[i][j] chính là một phần tử yên ngựa. Thuật toán cải tiến cho bài toán 3 này có độ phức tạp , tất nhiên là tốt hơn so với thuật toán ban đầu có độ phức tạp .Việc cài đặt cụ thể thuật toán này xin dành lại như là một bài tập cho các bạn độc giả. Bài toán 4 (bài toán số trung bình): Cho một dãy các số nguyên a1, a2, … , aN. Một phần tử akđược gọi là phần tử trung bình của dãy đã cho nếu tồn tại hai phần tử ai, aj (i≠j) sao cho ak = (ai + aj)/2. Chẳng hạn với dãy số 3, 7, 10, 22, 17, 15 ta có (a1 + a5)/2 = 10 = a3 nên a3 là một phần tử trung bình. Nhưng dãy 3, 8, 11, 17, 30 lại không có phần tử trung bình nào. Hãy viết chương trình đếm số phần tử trung bình của một dãy cho trước có N phần tử (N ≤ 10000). Về thực chất đây là một bài toán khá giống với bài toán 1, nhưng các bạn cần để ý tới điều kiện của N (N ≤ 10000) để tránh dẫn tới sử dụng một thuật toán sai (không chạy hết được các test của bài toán). Lời giải đơn giản cho bài toán có độ phức tạp là 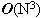 , lời giải này hoàn toàn trực tiếp đối với lời phát biểu của bài toán: , lời giải này hoàn toàn trực tiếp đối với lời phát biểu của bài toán: Vòng lặp kiểm tra tồn tại j và k cần N*N bước thực hiện (cần kiểm tra tất cả các cặp để xem a[i] có là trung bình cộng của cặp đó không). Do đó độ phức tạp của thuật toán sẽ là . Lời giải này có thể qua được khoảng 30% số test của bài toán, đo điều kiện về biến N.Tuy nhiên chúng ta có thể đạt được hiệu quả lớn hơn nhiều so với lời giải trên. Chúng ta có thể xác định được một phần tử nào đó có là trung bình cộng của hai phần tử khác không bằng một thuật toán có độ phức tạp thay vì thuật toán có độ phức tạp . Quan sát đầu tiên cho chúng ta nhận xét: nếu a[i] là trung bình cộng của a[j] và a[k] thì trong 2 số a[j], a[k] sẽ có một số nhỏ hơn hoặc bằng a[i], số còn lại sẽ lớn hơn hoặc bằng a[i].Giả sử dãy số của chúng ta đã được sắp theo thứ tự không giảm từ trước: a[0] 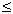 a[1] … a[N-1]. Hơn nữa chúng ta giả sử các số là phân biệt (tôi sẽ để trường hợp các số lặp cho các bạn như là một bài tập nhỏ), do đó a[0] < a[1] < … < a[N-1]. a[1] … a[N-1]. Hơn nữa chúng ta giả sử các số là phân biệt (tôi sẽ để trường hợp các số lặp cho các bạn như là một bài tập nhỏ), do đó a[0] < a[1] < … < a[N-1].Để kiểm tra a[i] có thể là một phần tử trung bình không, chúng ta trước hết xem xét a[i-1] và a[i+1]. Nếu như trung bình cộng của a[i-1] và a[i+1] là a[i] thì chúng ta kết luận ngay a[i] là một phần tử trung bình. Nhưng nếu không phải thì sẽ có hai trường hợp xảy ra: Trường hợp 1: trung bình cộng của a[i-1], a[i+1] lớn hơn a[i]. Khi đó a[i] không thể là trung bình cộng của a[i-1] với bất cứ phần tử a[j] nào mà j < i, và trung bình cộng của a[i-1] với bất cứ phần tử a[j] nào mà j > i+1 cũng sẽ lớn hơn a[i]. Do đó ta sẽ không cần thiết phải xem xét phần tử a[i-1] nữa. Trường hợp 2: trung bình cộng của a[i-1, a[i+1] nhỏ hơn a[i]. Khi đó a[i] sẽ không thể là trung bình cộng của a[i+1] với bất cứ phần tử a[j] nào mà j > i, và a[i] cũng không thể là trung bình cộng của a[i+1] với bất cứ phần tử a[j] nào mà j < i. Có nghĩa là phần tử a[i+1] sẽ không cần phải xét tới nữa. Thật tuyệt vì chúng ta dường như loại bỏ được rất nhiều các cặp cần xem xét chỉ sau một thao tác so sánh. Có thể áp dụng các nhận xét trên để đưa ra một thuật toán có độ phức tạp N thay vì N*N hay không? Câu trả lời là có, cùng với lập luận tương tự như trên chúng ta có nhận xét sau: Giả sử left < i và right > i. Giả sử avg(a[left], a[right]) > a[i] (avg là ký hiệu trung bình cộng). • a[i] không thể là trung bình cộng của a[left] với bất cứ a[j] nào mà j right. • Tương tự nếu avg(a[left], a[right]) < a[i] thì a[i] cũng sẽ không thể là trung bình cộng của a[right] với bất cứ a[j] nào mà j left. Nhận xét này dẫn chúng ta tới một thuật toán hiệu quả hơn. Chiến lược của thuật toán là chúng ta xét hai chỉ số left và right thỏa mãn: 1) left < i và right > i 2) a[i] không phải là trung bình cộng của bất cứ cặp đôi nào liên quan tới một phần tử a[j] nào mà left < j < right. Để bắt đầu ta khởi tạo left = i-1 và right = i+1 (do ta giả sử dãy là phân biệt và sắp xếp tăng dần nên điều kiện 2 luôn được thỏa mãn). Nếu avg(a[left], a[right]) = a[i] thì ta tăng biến đếm lên 1 đơn vị. Nếu avg(a[left], a[right]) > a[i] thì ta giảm left đi 1 đơn vị. Tất nhiên điều kiện 1 vẫn thỏa mãn, về điều kiện 2 thì ta biết rằng bất cứ a[j] nào mà left < j < right, a[j] đều không thể xuất hiện trong cặp có trung bình cộng bằng a[i]. Hơn nữa do (1) nên ta biết rằng a[i] cũng không thể là trung bình cộng của a[left] với bất cứ a[j] nào mà j i. Và rõ ràng là a[i] cũng không thể là trung bình cộng của a[left] với bất cứ a[j] nào mà j < left. Do đó a[i] không thể là trung bình cộng của a[left] với bất cứ a[j] nào, nên giảm left đi 1 đơn vị không mâu thuẫn với (2). Ngược lại nếu avg(a[left], a[right]) < a[i], chúng ta sẽ tăng right lên 1 đơn vị. Hoàn toàn tương tự ta có thể chứng minh các điều kiện 1 và 2 không bị vi phạm. Chúng ta sẽ dừng lại và kết luận a[i] không phải là một phần tử trung bình trong trường hợp left < 0 hoặc right = N. Và cài đặt của thuật toán là:  Trong mỗi lần lặp của vòng lặp while, biến chỉ số left sẽ được giảm đi 1 hoặc biến chỉ số right sẽ bị giảm đi 1. Do đó vòng lặp while này chỉ có thể chạy tối đa N lần trước khi kết thúc. Do đó độ phức tạp của thuật toán là N*N. Vì chúng ta giả sử a[0] < a[1] < … < a[N-1] và các phần tử là khác nhau nên chúng ta cần phải sắp xếp trước khi thực hiện thuật toán trên. Và tất nhiên chúng ta có thể chọn một thuật toán sắp xếp có độ phức tạp hoặc . Tóm lại là thuật toán sẽ có độ phức tạp là .Nếu như các phần tử không phải là phân biệt, thì sau khi sắp xếp xong chúng ta có thể sửa đổi đôi chút để thuật toán trên vẫn có thể làm việc được trong cả trường hợp này (phần này sẽ dành cho các bạn như là một bài tập nhỏ). Chú ý là trong thuật toán trên chúng ta đã sử dụng một thuộc tính của trung bình cộng: nếu x y và w z thì agv(x, w) agv(y, z). Tính chất này được gọi là tính đơn điệu. Nếu như chúng ta cần phải tính số lượng phần tử là tổng của hai phần tử, hay bất cứ giá trị nào thỏa mãn tính đơn điệu thì đều có thể giải quyết bằng một thuật toán có độ phức tạp là O(N2) thay vì một thuật toán có độ phức tạp .Các bạn có thể thấy rằng thuật toán trên cũng khá phức tạp và không quá dễ hiểu cho bài toán, lời giải thứ hai của bài toán khá gọn và dễ hiểu: do các số đều là số nguyên, ta lại cần đếm các số là trung bình cộng của hai số trong dãy, nên ta sẽ đánh dấu tất cả các tổng của hai số khác nhau (về vị trí chứ không phải về giá trị) trong dãy, sau đó duyệt lại dãy tổng này để đếm và đưa ra kết quả, cài đặt cụ thể của thuật toán này như sau: 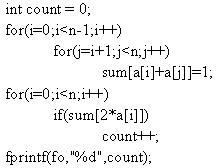 Độ phức tạp của thuật toán này cũng là , nhưng đơn giản và dễ hiểu hơn nhiều so với thuật toán trước.Mặc dù đã hết sức thận trọng và xem xét kỹ các ví dụ đưa ra trong bài viết, tuy vậy vẫn có thể không tránh khỏi các sai sót, rất mong nhận được sự đóng góp ý kiến của các bạn độc giả. Mọi góp ý, thắc mắc xin gửi về địa chỉ email: tuannhtn@yahoo.com. |
| URL của bài viết này::http://www.schoolnet.vn/modules.php?name=News&file=article&sid=2145 |
| © Cong ty Cong Nghe Tin hoc Nha truong | contact: schoolnet@vnschool.net |
Không có nhận xét nào:
Đăng nhận xét